How to use Text-to-Speech voice synthesis in GCP
【Overview】Text-to-Speech is powered by Google’s AI technology. It uses the API to convert text into natural and lifelike speech. Transcription data is sent to Text-to-Speech for speech synthesis through an API call, and then the synthesized human speech in a playable audio format is received in the response.
Imagine you have a voice – assisted application that can provide natural language feedback to your users through playable audio files. Your application may perform an action and then provide human speech as feedback to the user.
[Advantages]
- Improve the customer interaction experience with natural and lifelike intelligent responses;
- Enable users to interact with the voice interface in your devices and applications;
- Personalize the communication method according to the user’s preferred voice and language;
- Support multilingual pronunciation, reference link: (https://cloud.google.com/text-to-speech/docs/voices);
- Allow you to configure the speaking rate, pitch, volume, and sample rate (in Hertz).
[Practice]
Create a new service account
If your project doesn’t have a service account yet, create a new one. You must create a service account to use Text-to-Speech. Go to “Create service account”. In the Service account name box, enter a unique name for the new service account.
Assign a basic IAM role to the service account. Click the Select a role dropdown, then scroll down to Basics. You can select a role for this service account from the options shown in the right column. Click Continue.
为服务帐号创建 JSON 密钥
- 通过主导航菜单中的 IAM 和管理 -> 服务帐号选项访问服务账号,随时生成密钥和/或更改个人用户信息。
- 如需创建密钥,请点击服务帐号,然后选择密钥。点击添加密钥 -> 创建新密钥。创建 JSON 格式的密钥。
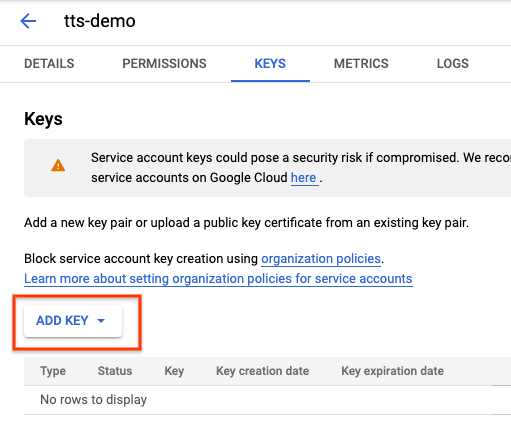
- 系统会自动下载选择的格式的新密钥。将此文件存储在安全的位置,并记下文件路径。在每个新的 Text-to-Speech 会话开始时的身份验证过程中,需要将 GOOGLE_APPLICATION_CREDENTIALS 环境变量指向此文件。这是对发送到 Text-to-Speech 的请求进行身份验证的重要步骤。密钥的唯一 ID 显示在服务帐号名称旁边。
设置身份验证环境变量
export GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"从文本合成音频
- 创建request.json
{
"input":{
"text":" Google Cloud Text-to-Speech enables developers to synthesize natural-sounding speech with 100+ voices, available in multiple languages and variants. It applies DeepMind’s groundbreaking research in WaveNet and Google’s powerful neural networks to deliver the highest fidelity possible. As an easy-to-use API, you can create lifelike interactions with your users, across many applications and devices. "
},
"voice":{
"languageCode":"en-gb",
"name":"en-GB-Standard-A",
"ssmlGender":"FEMALE"
},
"audioConfig":{
"audioEncoding":"MP3"
}
}
- 在 input 部分的 text 字段中指定要合成的文本,并在 audioConfig 部分指定要创建的音频类型
- 在 POST 命令正文的 voice 配置部分指定要合成的语音类型
- 执行文本转化命令
命令:
curl -s -X POST -H "Authorization: Bearer "$(gcloud auth application-default print-access-token) -H "Content-Type: application/json; charset=utf-8" -d @request.json "https://texttospeech.googleapis.com/v1/text:synthesize" | jq .audioContent | xargs> synthesize-output-base64.txt- 注:使用 gcloud auth application-default print-access-token 命令检索请求的授权令牌
- 将 synthesize-output-base64.txt 文件的内容解码到名synthesized-audio.mp3 的新文件
命令:
base64 synthesize-output-base64.txt -d > synthesized-audio.mp3
在音频应用中或音频设备上播放 synthesized-audio.mp3 的内容

